










目前全球熱門AI大語言模型(LLM)大多較「擅長」英文或簡體中文,台灣晶片設計大廠聯發科技旗下的聯發創新基地(MediaTek Research)在2月中正式發表並全面開源其最新的多模態基礎模型群——MediaTek Research Breeze 2(簡稱MR Breeze 2,模型開源連結),包括特別強化了對繁體中文理解能力的多模態語言模型Llama-Breeze2,以及台灣口音語音合成模型BreezyVoice;聯發創新基地歡迎開發者社群持續擴充並使用這些基礎模型,讓更貼近台灣在地使用者的客製化AI助理開發活動能蓬勃發展。
繁中多模態語言模型Llama-Breeze2是以Llama 3.2大型語言模型為基礎,除了繁體中文能力的最佳化,還整合了視覺語言模型(VLMs)以及函式呼叫(Function Calling)功能,支援不同應用場景的開發。BreezyVoice則是專為本地市場打造、針對台灣口音進行調整的語音合成模型(TTS),號稱僅需5秒鐘長度的音訊樣本就可生成高度擬真語音,用以實現智慧語音助理、客服系統與個人化語音應用。
以上兩套模型各有適用行動裝置/手機的3B「羽量級」參數規模版本,以及適合個人電腦(PC)的8B輕量級版本,讓開發者根據硬體資源選擇最適合的解決方案。除了模型開源外,聯發創新基地也首度開源搭載了3B版本Llama-Breeze2模型的Android作業系統APP(開源連結),以助力開發者探索如何將其導入智慧裝置與行動應用中。
Llama-Breeze2特色與優勢
全面提升了繁體中文知識的Llama-Breeze2,能讓AI助理更精確辨識處理台灣本地化語境與用語。根據聯發科提供的範例,當以「台灣夜市」為題,分別由Llama-Breeze2-3B與Llama 3.2產出的短文結果,可明顯看出前者對台灣夜市的知識深度和準確性較佳,如下圖:

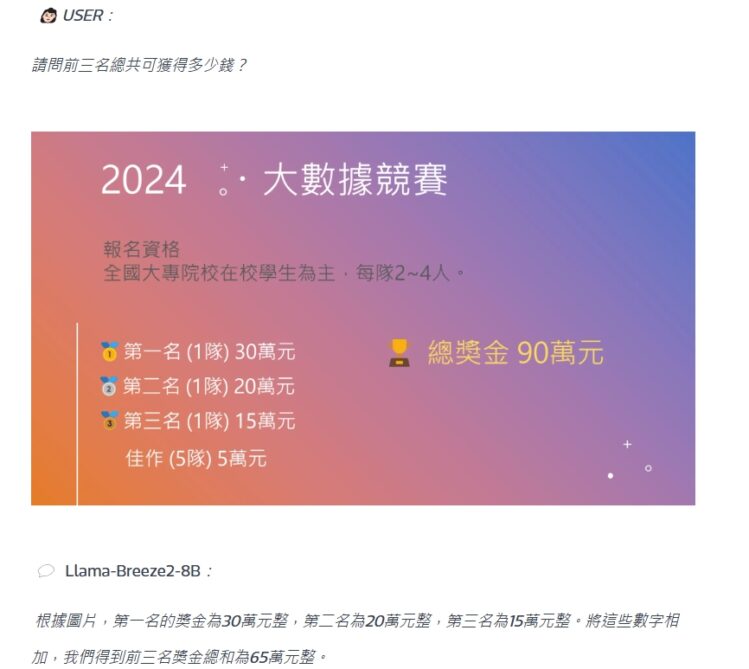
除了更了解繁體中文與台灣在地知識,Llama-Breeze2另一個特色是其多模態能力,因為整合視覺模型,能讓AI助理不僅讀得懂文字,也更會看圖,例如閱讀圖表、辨識圖片中的文字,或是識別景點。如下圖所示,該模型能從一場競賽的得獎公告中正確讀取前三名個別獎金金額,還能計算獎金總和。
Llama-Breeze2的另一個特色優勢是結合函式呼叫功能,能調用外部工具以加速完成特定任務,提升模型實用性並讓使用者與模型可以交互協作。此次聯發創新基地也同時將可直接部署到個人手機的羽量級Llama-Breeze2-3B模型Android APP開源,讓開發者能節省繁瑣的介接流程,專注應用功能創新,例如開發能針對台灣本地景點進行推薦介紹,或是具備即時翻譯功能的AI隨身助理;若行動裝置主晶片是聯發科天璣,該模型還能被搭載於其中的NPU加速執行,提升效率。
其他參考資源:MediaTek Research基礎模型主頁
(本文轉載自vMaker台灣自造者,原文連結:https://vmaker.tw/archives/73389)